A Proposal for Research
If I had the budget/compute power and time to research anything at the moment, this is what I would try researching. It’ll make sense in a bit, I swear.
The Problem
Training robotic policies to perform complex tasks is incredibly difficult. We have some success with generalist policies and existing reinforcement learning research, but they typically have limits on what they can accomplish.
The Routing Agent Architecture
A common pattern right now in robotics is to have a VLA (Vision Language Action Model) consume world state, vision, and some other inputs to generate a set plan, which in turn is utilized to call routing across varous sub systems/agents of the robot. This is very much like my capstone thesis project from back in ‘23.
These subsystems then are a combination of typical hard coded robotic actions, good old-fashioned standard control systems, and some individual task-focused RL agents. For instance, if we were to ask an armed robot to get me a snack (say, a clementine) in the kitchen, the robot would:
-
Load current world state data/context with current vision, deciding on a plan of action
- Plans might be generated in parallel, again like my capstone thesis, or checked against affordance functions, like SayCan or some other judge method to select the best course of action.
-
This plan is typically executed in series, calling internal functions as a agentic system would call tools. For our example, the first action would likely be navigating to the table where the robot knows where the orange is (let’s just assume it does, for simplicity). This would be the VLA referring to the location in its memory in some manner, and then the navigation task would determine some real world coordinates associated with it, and navigate the robot to that location via some typical SLAM system.
-
Once there, the VLA may check for the presence of the orange, but to do the actual grabbing, the VLA calls an appropriate submodel trained for that style of task, sometimes hyper specific. This can be a designed program, mixing vision models with hard coded control systems and instructions, or a full on reinforcement learning agent. The RL agent is, itself, a separately trained model. (Note - decision transformers [my slides on the topic] or other behavioral cloning-esque methods) could be utilized instead of RL.
-
And then navigate back to the user waiting or their treat.
This may seem like robots are essentially a set of multiple agents working together across microservices, and, well, yeah - that’s exactly how modern robotics generally works. While I do think that’s the best way to build out these incredibly complicated self-contained systems, I do so with only the experience of more complex builds always reaching for ROS. It’s a classic case of Conway’s Law, wherein the structure of the system is a reflection of the organization that built it. Since most robotics sofware packages are built by academics, whom in turn want to focus entirely on their focus or specialization within the vast field of robotics, no one wants to have to rebuild the navigation system and Kalman Filters for the umpteenth time. The result - lots of subsystemss that plug into one another in a manner that allows you to easily swap out any component for any other, sometimes with only a small translation layer between the two.
This approach does work, surprisingly well even despite the sheer level of complexity, for many types of applications. But there’s a reason you don’t see individual robots doing complicated and dangerous and expensive tasks - they don’t work reliably enough. Even specialized robotic builds - ones wherein the robot is specically built and programmed to complete a singular task - can be enormously complicated and requires significant engineering experience to make robust enough to be worth the substantial investment. You can’t scale this to work in many environments for many different tasks.
General Robot, reporting for duty
To combat this, we have generalist policies, which are exactly what they sound like. Attempts at building robot models that can individually perform all needed computation for deciding how to solve a task and handle it. You can see research in this manner across
Note that these are often called visuomotor or sensoriomotor models, as the model is outputting some value that maps directly to motor control in some manner.
These models tend to be gigantic, and training them is difficult. They struggle with long horizon or multi-step tasks, with some recent research attempting to combat this by breaking it into subtasks.
An aside
I was going to write more about that research, then maybe a bit more about current generalist policies successes and shortcomings, but frankly that immediately looked like a rabbit hole that I want to dive down into. That would, of course, completely detract from the point of this post, so I am going to just throw up my hands and reserve the joys of that deep research on future me. It has been awhile since I talked about the latest robotics AI papers.
This also underlines one of my caveats for this post - I am not as well read on the current state of the art as I’d like, but more importantly I’m not claiming that the idea I am proposing is necessarily original. I am simply unaware of anyone else proposing this particular combination of recent innovations.
My Proposal
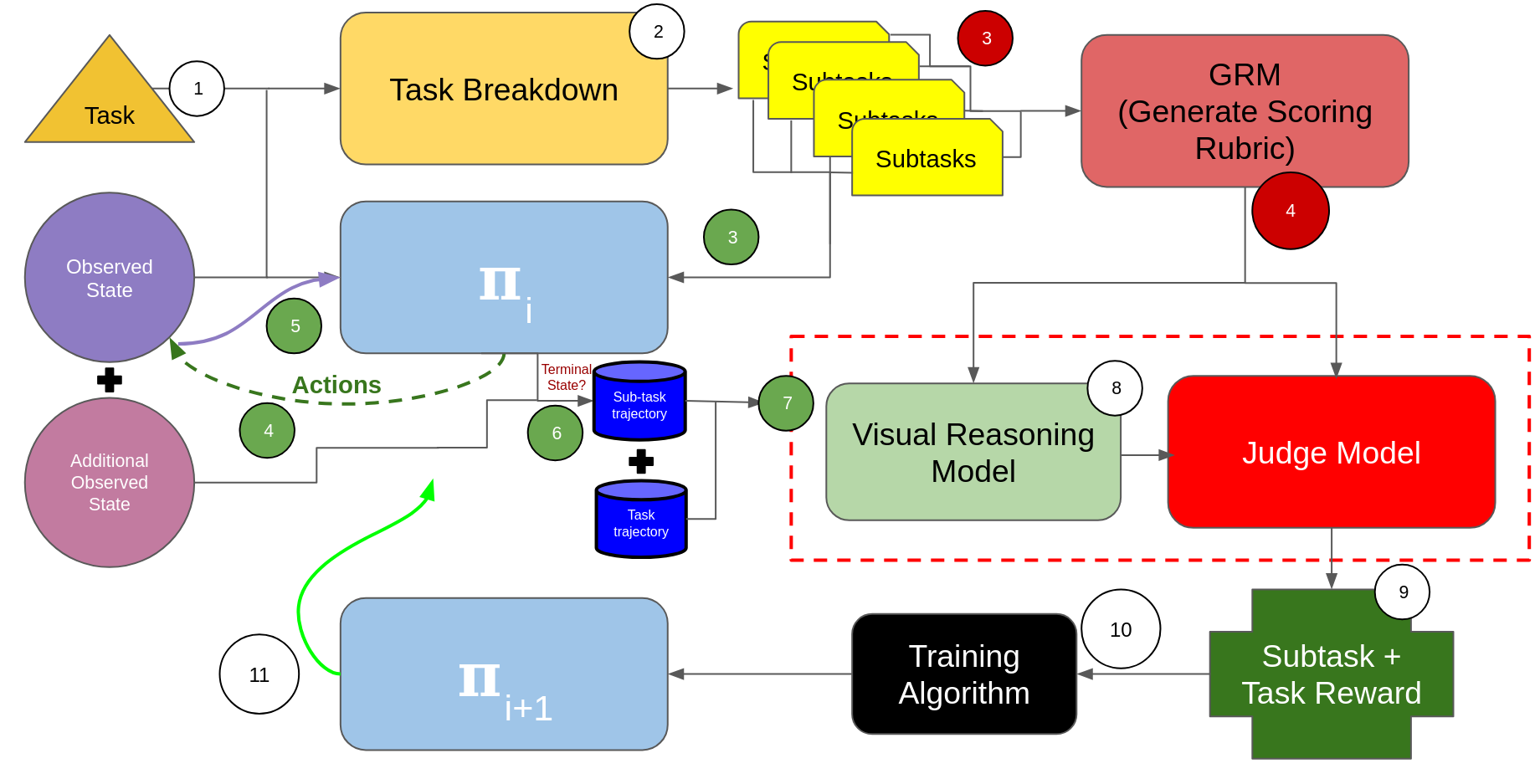
So what’s the idea I’m excited about and proposing about how to create better long horizon generalist policies? This:
Now, step by step:
- The task is fed into the Task Breakdown with the observable state - what the robot could realistically observe.
- A model generates a plan of action. This could be a multi step process, but for now we’ll just assume it’s a one-shot operation. The output is a series of sub tasks.
At this point, we’ll follow the green path - we’ll come back to the red path.
-
The subtasks are fed, in order, to the policy π, which is our target trained model.
-
The policy π produces a set of actions which affects the state. We then…
-
Observe the new state so that policy π can generate more actions until…
-
We hit a terminal state for the subtask. When this occurs, the episode’s trajectory is appended to the full task’s trajectory. We are also optionally collecting additional hidden data from the simulation (if it’s available). Aspects of the world state the robot could not necessarily observe at inference but might be useful for judging and adjusting the model in training.
-
Once we have hit a task-level terminal state, we feed the total trajectory (with a note of what subdivisions exist for subtasks) into our learning policy.
Let’s jump back to our red path for a moment.
-
The subtasks are sent over to our GRM. What’s that?
-
The GRM (Generative Reward Model) is an idea ripped from DeepSeek - I write and speak about it in depth here. It’s a model specifically designed to create a set of criterion to judge a goal, and then used to judge and justify that goal. We’re using it here to create a set of criterion for the movements and actions of the robot given the state. We use it here to create a set of “expected movements” and other criterion for each sub task, as well as the total combined task.
Our paths combined, let’s continue:
-
This is where the idea hits a big question mark - are we even close to this level of visual reasoning? Using the generated criterion as a backdrop, we use a visual reasoning model to determine what the robot is doing throughout the trajectories. This is then fed into a judge model to determine how closely the robot is following the defined criterion from the GRM.
-
We calculate the reward, noting subtask per turn rewards and overall task reward, per the methodology I just wrote and spoke about.
-
Given our reward, we then utilize a training algorithm (PPO? Some other variant?) to update the policy π, which is…
-
Then utilized to go through the whole process again.
Next Steps
There is no next steps, at least not for me. I don’t have the time or funds to pursue it at this juncture, but the idea kept itching at the back of my mind. I needed to write it down, express it aloud to scratch at that mental nagging.
Maybe one day I’ll be able ot try sometihng along these lines, or maybe it’ll inspire someone else. Or I’ll realize in the future this was a naive idea and laugh. But at least the idea is out there now.